Survey of whole population is called Census
Survey of a group od Population is called Sample
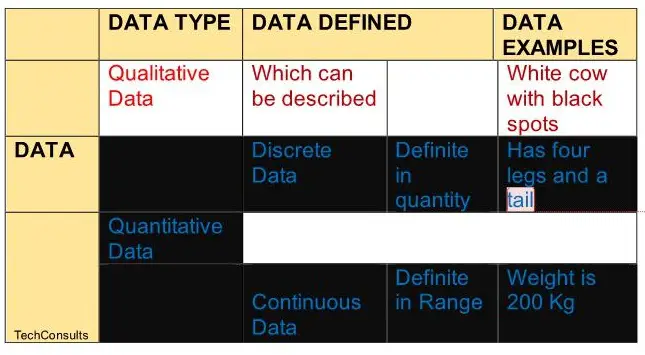
Data Types
Analog data – A sound note changing uniformly and is continuous such without jerks
Digital data – A sound note changing uniformly and is continuous such with jerks
Binary data – Used in computers and phones
A Binary Number is made up of only 0s and 1s.
100110 is a binary data- uses only two digits
Bit- Measure of one digit of binary data. The number above has 6 digits
Byte, Megabytes, Gigabytes, Terabytes – are the units of binary data measurement.
Data is processed, analysed to get information. The information is used in ‘Monitoring & Control’ processes, which is an important group of ‘Project Management Processes’. The data can be represented diagrammatically as
Bar Charts, Pie Charts, Line Graphs, Scatter diagram, Histograms, Frequency Distribution etcetera
Probability- Probability is a branch of mathematics that deals with occurrence of a random event. For example,
When a coin is tossed in the air, the possible outcomes are Head and Tail. Hence probability of either head or tail is1/2.
When a dice having six faces numbering 1, 2, 3, 4, 5, 6, is thrown there I probability that any number from 1 to 6 can come on top. Hence probability of any number coming on top is 1/6
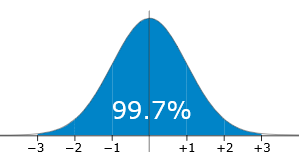
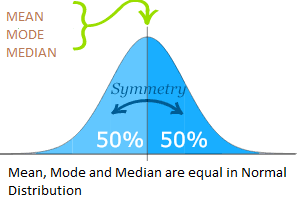
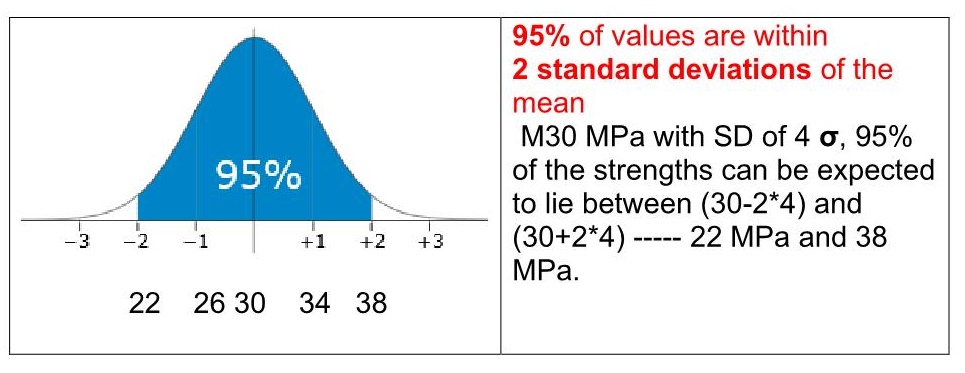
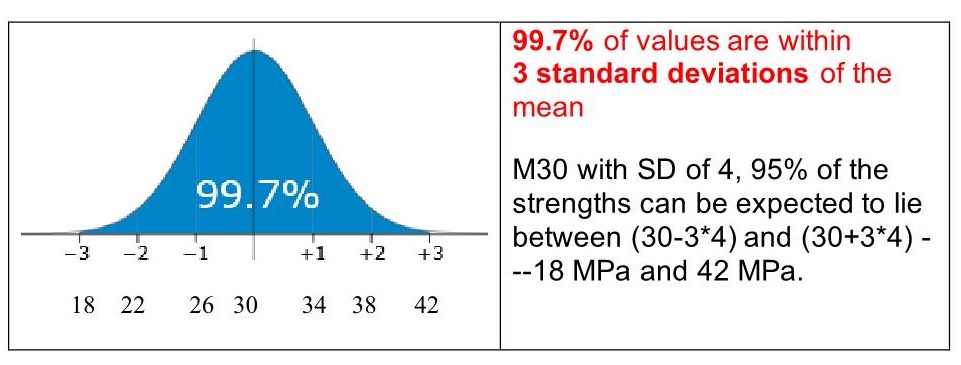
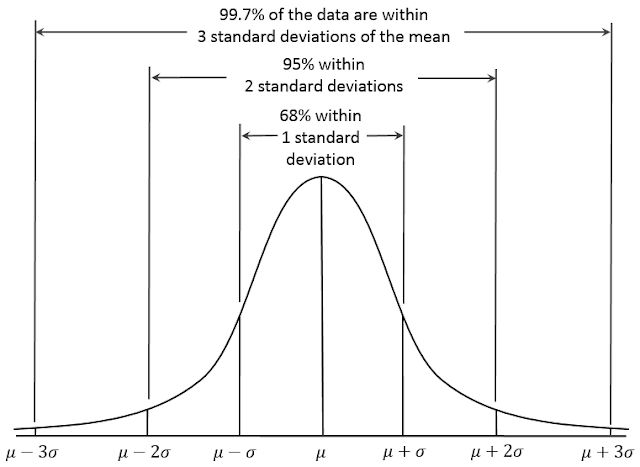
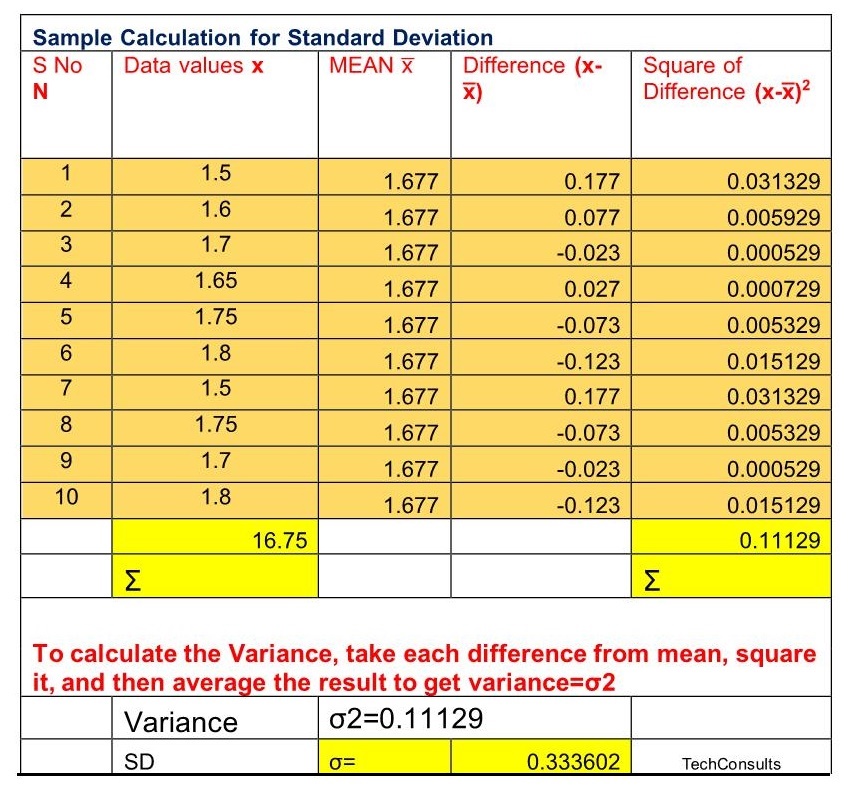
Mean, Median and Mode are the measures of central value of a data set.
Mean
The mean of data set 14,18,12,17,12,13,11,10, 9, 8= sum of all numbers/number of data
(14+18+12+17+12+13+11+10+9+8) / 10 = 12.4 is the mean
Mode is the value that occurs most time
Median of data 6,8, 9, 10, 11, 12, 12, 14, 14, 17, 18
Arrange the data in a sequence. The central figure 12 is the median value. If centre dataset has even numbers, then find the average of two central values to get the Median value.
If an event is random, it means that it does not seem to follow a definite plan or pattern or outcome.